Steve McQueen: TORCS with Actor-Critic/DDPG Learning
Published: January 23, 2018
Background
Steve McQueen is a culminating project completed for ECE457B: Fundamentals of Computational Intelligence. The class covered a variety of topics on machine learning, including artificial neural networks. This was an exercise to go above and beyond the class and experiment with a novel new type of learning that Google has been pioneering, called Deep Deterministic Gradient Policy (DDPG) or Actor-Critic Reinforcement learning.
What is DDPG or Deep-Q Learning?
This new type of network was made possible in 2015 with the reinforcement learning based Deep-Q Network1. Reinforcement learning is a type of machine learning where the learning occurs by being allowed to roam free within an environment and study the consequences of actions. This is a massive advantage over traditional networks which require a large amount of labelled, classified, or otherwise human-processed data to train and verify based on. In the case of a simulated video game environment, it can run essentially limitless simulations and continually improve.
DDPG is a variation of the Deep-Q network which allows for continuous (rather than discrete) action using a pair of Actor and Critic networks. It also extends upon Deterministic Policy Gradient2, relying on new techniques in batch normalization3. These improvements mean that it is possible to reduce error between the Actor and Critic enough that it is possible for the Critic to directly adjust the weights of the the Actor network.
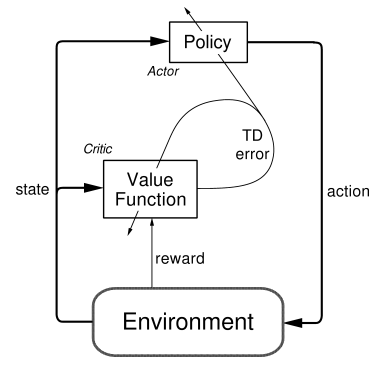
Diagram from Reinforcement Learning by Sutton & Barto4.
The Critic network is responsible for weighting the value of Actor decisions, providing a dynamic reward rating for each action. The Actor network looks at environment state inputs, and determines the best action based on the Critic-supplied weights.
In order to fully explore the environment, the network must be forced to make decisions that are unexpected or sub-optimal. To do this, a stochastic noise process was utilized to disturb the controls during the training process. This forces the networks to rate all possible paths by using a type of randomness for generating series. The Ornstein-Uhlenbeck5 process was chosen due to the adjustable mean-reverting properties which could be chosen per control. This meant that noise could be generated with a mean that represents typical values for each control parameter (ie. typical amount of acceleration, steering, or braking).
Further, in order to exploit the batch renormalization process that makes DDPG so useful, Experience Replay is used to run training off mini-batches of randomized observations from memory, rather than the most recently observed states. This improves stability by reducing the likelihood of the network getting stuck in local minima due to over-fitting. Due to this, networks can be trained more aggressively without worry of getting too used to a certain series of states.
Creating Steve McQueen
In order to create Steve McQueen, several tools were required to interface with TORCS and create and train the neural networks.
- OpenAI Gym-based gym_torcs project was used to simplify the control and sensor interface with the TORCS environment
- Keras was used as the interface to the core TensorFlow-based networks
- vTorcsRL client allowed for virtualization of the TORCS client, allowing for rapid training by running faster than real-time and increased command-line control
The TORCS game provides a sensor output of 17 LIDAR-equivalent range sensors to provide navigation. It requires inputs for the steering angle, acceleration/gas pedal, brake, and gear choice. These sensor signals are combined with the inputs and stored in the Frame Replay buffer for use in mini-batch training. The frame replay randomizes the order of frames in order to avoid over-fitting and allow an aggressive Critic network learning rate (10 times the Actor network).
The other novel trick of DDPG is that the Critic network directly updates the gradients of the Actor network. This is possible with Tensorflow Gradient Computation. The Actor network weights are directly exposed for updating, and the Critic network produces new values by maximizing the Reward value of the state inputs. During training, the stochastic noise process generates random nudges to the controls (away from the current optimum path). After several hundred training runs, the environment is adequately explored and the weights of the network have reached stable values. Steve McQueen is off and away…
-
Human-level control through deep reinforcement learning, Mnih et al, Nature Volume 518 ↩
-
Deterministic Policy Gradients, Silver et al., Proceedings of the 31st International Conference on Machine Learning ↩
-
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, Sergey Ioffe and Christian Szegedy, Proceedings of the 32nd International Conference on Machine Learning ↩
-
Reinforcement Learning, Richard Sutton and Andrew Barto ↩
-
Ornstein-Uhlenbecker Process, Encyclopedia of Math ↩



